Android扩展知识点
点击阅读前文前, 首页能看到的文章的简短描述
点击阅读前文前, 首页能看到的文章的简短描述
点击阅读前文前, 首页能看到的文章的简短描述
frida 代码结构:frida-core: Frida core library intended for static linking into bindingsfrida-gum: Low-leve……
frida-core: Frida core library intended for static linking into bindings
frida-gum: Low-level code instrumentation library used by frida-core
bindings:
frida-python: Frida Python bindings
frida-node: Frida Node.js bindings
frida-qml: Frida Qml plugin
frida-swift: Frida Swift bindings
frida-tools: Frida CLI tools
capstone: instruction disammbler
frida-gum 本身就是一种跨平台的设计. 有两个点需要处理统一: 1. 针对 CPU 架构的代码 2. 针对操作系统 (Backend) 的代码. 同时要在这两个点上构建 CPU/OS 无关代码, 以及规定一些统一的接口.
frida-gum/gum/arch-* 定义的是与 CPU 架构有关的代码, 也就是汇编级操作, 比如汇编指令的读 / 写 / 修复.
frida-gum/gum/backend-* 分两种情况: 1. 定义的是与操作系统有关的代码, 更多是一些内存 / 进程等操作 2. 对 arch 层级代码的封装成统一逻辑
frida-gum/* 对 arch 和 backend 的抽象封装成上层的平台 / 架构无关代码.
frida-gum/bindings/gumjs/:
分 V8 和 Duktape 两个引擎,实现了 Module、Memory、NativeFunction 等功能(https://www.frida.re/docs/javascript-api/)
index.js:
vm VM 虚拟机的 wrapper
classFactory class 的 wrapper
available 逻辑变量, 指明当前的进程是否载入了虚拟机
androidVersion 当前版本号
enumerateLoadedClasses 枚举所有加载的类
enumerateLoadedClassesSync 上面那个 API 的同步版本, 载入完毕才将所有的类作为一个数组返回
enumerateClassLoaders Android N 以上的支持
enumerateClassLoadersSync 同上
classFactory.js:
use: 找到类
implementation: 实现一个函数
overloads:
$new $alloc $init
vm.js:
getEnv
perform
attachCurrentThread
DetachCurrentThread
android.js
/global Memory, Module, NativeCallback, NativeFunction, NULL, Process/
getApi
ensureClassInitialized
getAndroidVersion
getAndroidApiLevel
getArtMethodSpec
getArtThreadSpec
getArtThreadFromEnv
withRunnableArtThread
withAllArtThreadsSuspended
makeArtClassVisitor
makeArtClassLoaderVisitor
cloneArtMethod
env.js
JNIEnv 的 wrapper

frida 兼容了低版本的 Android, 低于 Android 5.0 时,采用 Dalvik 虚拟机,其核心实现在 replaceDalvikImplementation 函数中。
frida 的 Dalvik hook 和 xposed 的 hook 原理相同,都是把要 hook 的 java 函数变成 native 函数,并修改函数的入口为自定义的内容,这样在调用时就会执行自定义的代码。
首先我们看一下 Dalvik 虚拟机执行 java 函数过程:
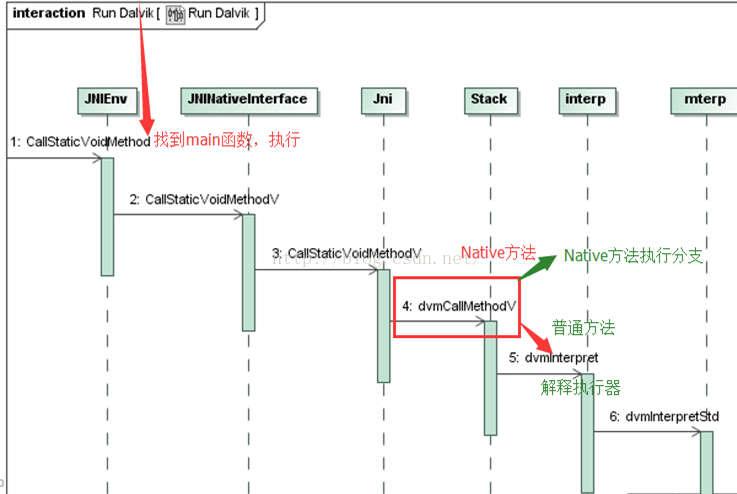
第 4 步 dvmCallMethodV 会根据 accessFlags 决定调用 native 还是 java 函数,因此修改 accessFlags 后,Dalvik 会认为这个函数是一个 native 函数,便走向了 native 分支。
Java 层的每一个函数在 Dalvik 中都对应一个 Method 数据结构,在源代码中定义如下:
1 | //https://android.googlesource.com/platform/dalvik/+/6d874d2bda563ada1034d2b3219b35d800fc6860/vm/oo/Object.h#418 |
replaceDalvikImplementation 修改了 method 中的 accessFlags、registersSize、outsSize、insSize 和 jniArgInfo,将原 java 函数对应的结构体修改为一个 native 函数,并调用 dvmUseJNIBridge(dvmUseJNIBridge 实现代码)为这个 Method 设置一个 Bridge,改变结构体中的 nativeFunc,指向自定义的函数。
1 | function replaceDalvikImplementation (fn) { |
自定义的 js 代码如何生成?
implement 的实现
1 | function implement (method, fn) { |
在自定义的代码里调用原函数?
frida 的 ART hook 实现也是把 java method 转为 native method, 但 ART 的运行机制不同于 Dalvik, 其实现也较为复杂,这里从 ART 运行机制开始解释。
ART 是一种代替 Dalivk 的新的运行时, 它具有更高的执行效率。ART 虚拟机执行 Java 方法主要有两种模式:quick code 模式和 Interpreter 模式。
即使是在 quick code 模式中,也有类方法可能需要以 Interpreter 模式执行。反之亦然。解释执行的类方法通过函数 artInterpreterToCompiledCodeBridge 的返回值调用本地机器指令执行的类方法;本地机器指令执行的类方法通过函数 GetQuickToInterpreterBridge 的返回值调用解释执行的类方法;
ART 中的每一个函数都对应一个 ARTMethod 结构体,其中 entry_point_from_interpreter_ 和 entry_point_from_quick_compiled_code_ 分别表示两种模式的调用入口
ARTMethod 结构如下:
1 | //http://androidxref.com/8.1.0_r33/xref/art/runtime/art_method.h#708 |
ART 的执行流程如下图:
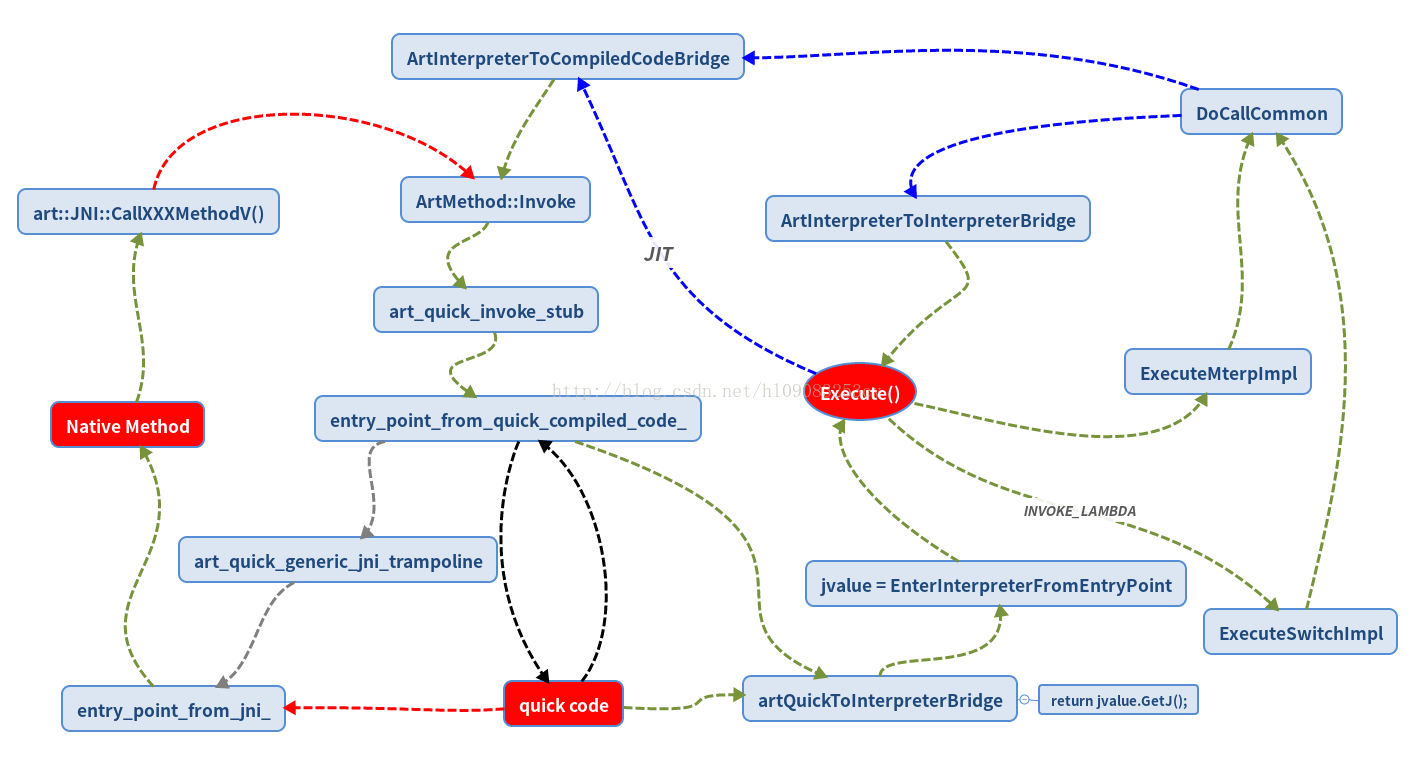
如图所示,对于一个 native method, ART 虚拟机首先会尝试 quickcode 模式执行,检查 ARTMethod 结构中的 entry_point_from_quick_compiled_code_ 成员,这里分 3 种情况:
如果函数已经存在 quick code, 则指向这个函数对应的 quick code 的起始地址,而当 quick code 不存在时,它的值则会代表其他的意义;
当一个 java 函数不存在 quick code 时,它的值是函数 artQuickToInterpreterBridge 的地址,用以从 quick 模式切换到 Interpreter 模式来解释执行 java 函数代码;
当一个 java native(JNI)函数不存在 quick code 时,它的值是函数 art_quick_generic_jni_trampoline 的地址,用以执行没有 quick code 的 jni 函数;
因此,如果 frida 把一个 java method 改为 jni method, 显然是不存在 quick code,这时需要将 entry_point_from_quick_compiled_code_ 值修改为 art_quick_generic_jni_trampoline 的地址。
art_quick_generic_jni_trampoline 函数实现比较复杂(代码分析),主要负责 jni 调用的准备,包括堆栈的设置,参数的设置等, 该函数最终会调到 entry_point_from_jni_,即 jni 函数的入口。
因此,frida 把 java method 改为 jni method,需要修改 ARTMethod 结构体中的这几个值:
access_flags_ = native
entry_point_from_jni_ = 自定义代码的入口
entry_point_from_quick_compiled_code_ = art_quick_generic_jni_trampoline 函数的地址
entry_point_from_interpreter_ = artInterpreterToCompiledCodeBridge 函数地址
frida 对 ARTMethod 的修改在 replaceArtImplementation 函数中:
1 | patchMethod(methodId, { |
patchMethod 实现:
1 | function patchMethod (methodId, patches) { |
getArtMethodSpec 实现:
1 | function _getArtMethodSpec (vm) { |
参考:
采坑记录:
ANDROID_NDK_ROOT must be set to the location of your r15c NDK.
解决办法:
设置环境变量 ANDROID_NDK_ROOT 为 ndk_r15c,必须为 r15 版本,我只是在当前 shell 里 export ANDROID_NDK_ROOT=/home/xxx/ndk-path 时无法编译通过,设为系统环境变量时,编译才通过。
Dependency ‘glib-2.0’ not found
1 | meson.build:123:0: ERROR: Dependency 'glib-2.0' not found, tried Extra Frameworks and Pkg-Config: |
实际运行 pkg-config –modversion glib-2.0 时,发现 glib-2.0 是存在的,出现以上错误是因为路径中包含中文!!!
这几年手游加速器很火。以光环为代表,进行C层的HOOK,既可以实现加速,又可以免Root保证手机安全。
a. 什么是加速?
加速就是改变游戏的运行速度。
b. 怎么样才能加速?
根据不同的引擎有不同的加速方法。关键还是在认识引擎上。
市面上大多数的游戏引擎大致可以分为 cocos2dx、Unity3d、Unreal、白鹭等。接下来我们分开来讲解各个引擎的加速方案。
cocos2dx 引擎一般是会有一个cocos2dx引擎动态库。由于cocos2dx是开源的软件,所以cocos2dx的引擎动态库的名字可以自定义。但是判断是不是cocos2dx引擎的游戏可以查看Java代码目录,是否有org/cocos2dx/目录,如果有这个目录就是cocos2dx引擎。
coco2dx游戏有个setTimeScale函数,这个函数用来控制运行时间。timeScale的值越大运行速度越快,timeScale值越小运行速度越慢。但是一般的情况下开发者不会去调用setTimeScale。所以我们基本没机会通过HOOK来改变setTimeScale的值。但是我们可以通过引擎的Director来实现。 Director 来有个定时器Scheduler,在每帧更新的时候都会调用Update(float delay)。而update函数里面则会调用timeScale的值,来乘以delay得到运行最终的时间。所以改变delay的值也可以达到加速减速的效果。
Uity3d 引擎是一个闭源软件,所以会有统一的动态库libunity.so。所以只要看到有libunity.so动态库,就基本确定是Unity3d游戏。
Unity3d游戏照样也是有一个setTimeScale函数。所以通过Hook 来达到更改timeScale的值,即能达到加速减速效果。但是Unity3d游戏一般通过C#来开发。然后通过il2cpp或者mono运行时来执行。所以我们要通过Hook il2cpp或者mono的运行时方法来调用setTimeScale。
il2cpp的关键函数是il2cpp_method_get_class、il2cpp_class_from_name、il2cpp_class_get_method_from_name
mono的关键函数是mono_get_object_class、mono_class_from_name、mono_class_get_method_from_name
通过HOOK这些函数,就可以更改timeScale的值了。
其它游戏引擎
libc.so中有gettimeofday函数。我们通过Hook 系统的gettimeofday函数来改变时间的流逝速度,也能达到加速的目的。
javascript
这个示例代码使用Frida框架来调用Unity游戏引擎中的Mono类方法。它首先通过attach到目标进程和获取相关模块的基址来获取Mono类和方法信息。然后,它构造了一个包含参数的调用,并使用mono_runtime_invoke函数来调用方法。最后,它使用mono_object_to_string函数来获取返回值并打印出来。请注意,这个示例代码仅供参考,实际使用时需要根据具体情况进行修改。
1 | // attach到目标进程 |
C
这个示例代码使用C语言和Frida框架来调用Unity游戏引擎中的Mono类方法。它首先初始化Frida并连接到目标进程,然后获取UnityPlayer.dll模块基址和Mono类和方法信息。接着,它构造了一个包含参数的调用,并使用frida_runtime_invoke_method函数来调用方法。最后,它使用frida_value_to_string函数来获取返回值并打印出来。请注意,这个示例代码仅供参考,实际使用时需要根据具体情况进行修改。
1 |
|
1 | double round(double value, unsigned int decimal_places) { |
visibility1 |
GNU C 的一大特色就是attribute 机制。
试想这样的情景,程序调用某函数A,A函数存在于两个动态链接库liba.so,libb.so中,并且程序执行需要链接这两个库,此时程序调用的A函数到底是来自于a还是b呢?
这取决于链接时的顺序,比如先链接liba.so,这时候通过liba.so的导出符号表就可以找到函数A的定义,并加入到符号表中,链接libb.so的时候,符号表中已经存在函数A,就不会再更新符号表,所以调用的始终是liba.so中的A函数。
为了避免这种混乱,所以使用
1 | __attribute__((visibility("default"))) //默认,设置为:default之后就可以让外面的类看见了。 |
设置这个属性。
visibility用于设置动态链接库中函数的可见性,将变量或函数设置为hidden,则该符号仅在本so中可见,在其他库中则不可见。
g++在编译时,可用参数-fvisibility指定所有符号的可见性(不加此参数时默认外部可见,参考man g++中-fvisibility部分);若需要对特定函数的可见性进行设置,需在代码中使用attribute设置visibility属性。
编写大型程序时,可用-fvisibility=hidden设置符号默认隐藏,针对特定变量和函数,在代码中使用attribute ((visibility("default")))另该符号外部可见,这种方法可用有效避免so之间的符号冲突。
经在代码中测试,
C++的extern __attribute__((visibility("default")))会导出函数参数,
C的extern "C" __attribute__((visibility("default")))的方式不会导出函数参数,两者不能通用。
version-script1 | set_target_properties(your_so_or_exe PROPERTIES LINK_FLAGS "-Wl,--version-script=${CMAKE_CURRENT_SOURCE_DIR}/symbol.version") |
symbol.version:
1 | { |
ETH 2.0 节点分为执行客户端、共识客户端、验证软件,同步数据节点无论是快照同步还是完整存档,都需要同步启动执行客户端和共识客户端。
Nethermind1 | sudo apt-get update && sudo apt-get install libsnappy-dev libc6-dev libc6 unzip |
添加下面配置到nethermind/configs/mainnet.cfg
1
2
3
4
5
6
7
8
9
10"JsonRpc": {
"Enabled": true,
"Timeout": 20000,
"Host": "127.0.0.1",
"Port": 8545,
"EnabledModules": ["Eth", "Subscribe", "Trace", "TxPool", "Web3", "Personal", "Proof", "Net", "Parity", "Health"],
"EnginePort": 8551,
"EngineHost": "127.0.0.1",
"JwtSecretFile": "keystore/jwt-secret"
},
启动Nethermind
1
2
3
4cd nethermind
./Nethermind.Launcher
# 选择具体配置,或者
./Nethermind.Runner --config mainnet
Prysm1 | mkdir prysm && cd prysm |
在https://beaconstate.ethstaker.cc/上确认slot编号对应的State root. 如果一致,表明所使用的检查点是正确的。
1 | curl -s http://127.0.0.1:3500/eth/v1/beacon/headers/finalized | jq .'data.header.message' |
https://github.com/hyperledger/besu/releases
https://geth.ethereum.org/downloads/
https://downloads.nethermind.io/
https://github.com/sigp/lighthouse/releases/latest
https://github.com/status-im/nimbus-eth2/releases/latest
https://github.com/prysmaticlabs/prysm/releases/latest
可信检查点列表
https://eth-clients.github.io/checkpoint-sync-endpoints/
1 | 安装vcpkg和openssl |
在windows 10/11中登录方式很多,如果提前设置了Windows Hello 登录(PIN)可能导致账号不能登录,根据我的测试结果要进行以下几步操作:
仅允许对此设备上的Microsoft账户使用Windows Hello 登录。MacOS平台的ffmpeg编译脚本,包含x264、x265、fdk-aac、opus以及openssl和rtmp库。
注释中有相关包的下载地址,需要先下载解压。
如果需要openssl则把openssl的相关的脚本注释去掉,并在ffmpeg脚本参数–extra-libs中添加上 -lssl -lcrypto。
如果需要rtmp库,则必须启用openssl,并在ffmpeg脚本参数中启用–enable-rtmp,现在是禁用状态。(其实没必要启用,只要支持flv格式就推拉流)
1 |
|
Ubuntu、Centos和Windows三平台的ffmpeg编译脚本,包含x264、x265、cuda加速、fdk-aac、opus以及openssl和rtmp库。
注释中有相关包的下载地址,需要先下载解压。
Windows需要安装msys2,并在mingw64下编译。
如果需要openssl则把openssl的相关的脚本注释去掉,并在ffmpeg脚本参数--extra-libs中添加上 -lssl -lcrypto。
如果需要rtmp库,则必须启用openssl,并在ffmpeg脚本参数中启用--enable-rtmp,现在是禁用状态。(其实没必要启用,只要支持flv格式就推拉流)
1 |
|
1 |
|
1 |
|
Visual Studio 2022
Pro: TD244-P4NB7-YQ6XK-Y8MMM-YWV2J
Enterprise: VHF9H-NXBBB-638P6-6JHCY-88JWH
Visual Studio 2019
Pro: NYWVH-HT4XC-R2WYW-9Y3CM-X4V3Y
Enterprise: BF8Y8-GN2QH-T84XB-QVY3B-RC4DF
1 | sudo docker pull centos:centos7 #centos:centos8 centos:latest #下载centos镜像 |
注意:为了能够保存(持久化)数据以及共享容器间的数据,docker一定使用-v挂载主机目录到容器,比如上面启动容器的 docker -v 参数。
宝塔默认密码使用 : bt default 查看,登录进去修改即可
1 | sudo apt-get -y install apt-transport-https ca-certificates curl software-properties-common |
1 | sudo yum install -y yum-utils device-mapper-persistent-data lvm2 |
修改daemon配置文件/etc/docker/daemon.json来使用加速器
1 | sudo mkdir -p /etc/docker |
进入 Settings -> Code Style -> Java或C/C++ ,在右边选择 “Code Generation” Tab,然后找到 Comment Code 那块,把
Line comment at first column
Block comment at first column
去掉前面两个的复选框,这样注释就靠近代码块了。
选上Add a space at comment start就会在代码块前添加一个空格。
centos 7 安装前置依赖
1 | sudo yum install git python-devel libffi-devel graphviz-devel elfutils-libelf-devel \ |
ubuntu 18.04+ 安装前置依赖
1 | sudo apt install git build-essential cmake python3-dev libncurses5-dev libxml2-dev \ |
下载&编译
1 | git clone git@github.com:llvm/llvm-project.git -b release/11.x |
如果只要编译clang,在cmake命令添加定义 -DLLVM_ENABLE_PROJECTS=clang;LLVM_ENABLE_PROJECTS可用的项目有clang;clang-tools-extra;compiler-rt;debuginfo-tests;libc;libclc;libcxx;libcxxabi;libunwind;lld;lldb;mlir;openmp;parallel-libs;polly;pstl
默认会编译所有平台,可以通过LLVM_TARGETS_TO_BUILD指定平台,可用平台有AArch64, AMDGPU, ARM, BPF, Hexagon, Mips, MSP430, NVPTX, PowerPC, Sparc, SystemZ, X86, XCore
linux和windows需要同时启用UTC,或者linux单独禁用UTC
1 | sudo mv /etc/localtime /etc/localtime.bak |
1 | # ubuntu |
1 | sudo timedatectl set-local-rtc 1 |
1 | reg add HKLM\SYSTEM\CurrentControlSet\Control\TimeZoneInformation /v RealTimeIsUniversal /t REG_DWORD /d 1 |
linux和windows需要同时启用UTC,或者linux单独禁用UTC
1 | sudo mv /etc/localtime /etc/localtime.bak |
1 | # ubuntu |
1 | sudo timedatectl set-local-rtc 1 |
1 | reg add HKLM\SYSTEM\CurrentControlSet\Control\TimeZoneInformation /v RealTimeIsUniversal /t REG_DWORD /d 1 |
对于点击 <a target='_blank'> 标签打开新 tab 页的场景,Puppeteer目前(2019-03,v1.13.0)没有现成的 API 支持。因此需要一些 walkaround 来解决。有几个方案。
1 | url = await page.evaluate('() => $("a").attr("href")') |
代码如下。这个方案的问题在于,拿到 detail_page 时并不知道页面是否 load 完成了,在这个时候调用 .waitForNavigation() 可能会超时报错(因为没有 load 事件被 fire)。如果页面有 AJAX 请求,你可能需要写额外的 waitForSelector 来确保你要的数据已经在页面上。
1 | # 点击完后出现新 tab 页 |
使用VSCode进行查找、替换时,经常需要用到正则表达式,一段时间不用就忘了,每次要用的时候都要耽误很多时间去查找,所以整理了一份很全的放在这里。这个其实是.NET使用的正则表达式,VSCode也是一样的,微软系的产品(比如Visual Studio等)应该都是使用这个标准的。
本文只列举和翻译了常用的一些,完整内容请参照微软官方文档
注意事项:在VSCode中使用时,要先把通配符开关打开(开关是查找输入框右边的”.*”符号)
| 转义字符 | 匹配内容 |
|---|---|
| \t | tab |
| \r | 回车符号\r |
| \n | 换行符号\n |
| \uxxxx | 匹配Unicode编码为xxx的字符,如\u0020匹配空格,这个符号可以用来帮助匹配中文,后面说 |
| \ | 特殊符号转义,如”*“ ,转义后匹配的是字符”*”, “(” 匹配的是括号”(“ |
| [字符序列] | 匹配[ ]中的任意字符,如[ae],字符a和字符e均匹配 |
| [^字符序列] | 匹配不在[ ]中的任意字符,如[^ae]除了a和e,其他字符都匹配 |
| [字符1-字符2] | 匹配在[ ]之间的任意字符,如[a-x],就是匹配a和x之间的所有字符(包括a和x) |
| . | 匹配任意单个字符(除了\n) |
| \w | 匹配所有单词字符(如”a”,“3”,“E”,但不匹配”?”,”.”等) |
| \W | 和\w相反,匹配所有非单词字符 |
| [\u4e00-\u9fa5] | 利用区间和\u转义符号,匹配中文(该区间包含2万个汉字),可以当做中文版的\w使用 |
| \s | 匹配空格 |
| \S | 和\s相反,匹配非空格 |
| \d | 匹配数字字符,如”1”,“4”,”9”等 |
| \D | 和\d相反,匹配除了数字字符外的其他字符 |
| * | 将前面的元素匹配0到多次,如”\d*.\d”,可以匹配”19.9”,”.0”,“129.9” |
| + | 将前面的元素匹配1到多次,如”be+”,可以匹配”be”, “beeeeee” |
| ? | 将前面的元素匹配0次或者一次,如”rai?n” 可以且只可以匹配 “ran” 或者 “rain” |
| {n} | n是个数字,将前面的元素匹配n次,如”be{3}“可以且只可以匹配 ”beee” |
| {n, m} | 将前面的元素匹配至少n次,最多m次,如”be{1,3}” 可以且只可以匹配”be”,“bee”, “beee” |
| | | 相当于”或”,表示匹配由 |
| $n | n是个数字,这个是替换时使用括号( )将匹配的patter分割成了几个元素,然后在替换的patter里面使用,类似于变量。如果查找patter是”(\w+)(\s)(\w+)”,那么$1就是(\w+),$2是(\s),$3是(\w+),替换patter是$3$2$1,那么替换结果就是(\w+)(\s)(\w+)。假设匹配到的是”one two”,那么$1,$2,$3分别为”one”, “ “, “two”,替换后的结果为”two one”. |
正则表达式除了匹配字符外,还可以对匹配的上下文做要求,比如要求匹配必须从一行的开头开始,感觉用的不是特别多,需要的请参照本文开头给出的链接。
凡有名者,皆为左值
首先不考虑引用以减少干扰,可以从2个角度判断:左值可以取地址、位于等号左边;而右值没法取地址,位于等号右边。
1 | int a = 5; |
再举个例子:
1 | struct A { |
可见左右值的概念很清晰,有地址的变量就是左值,没有地址的字面值、临时值就是右值。
引用本质是别名,可以通过引用修改变量的值,传参时传引用可以避免拷贝,其实现原理和指针类似。 个人认为,引用出现的本意是为了降低C语言指针的使用难度,但现在指针+左右值引用共同存在,反而大大增加了学习和理解成本。
左值引用大家都很熟悉,能指向左值,不能指向右值的就是左值引用:
1 | int a = 5; |
引用是变量的别名,由于右值没有地址,没法被修改,所以左值引用无法指向右值。
但是,const左值引用是可以指向右值的:
1 | const int &ref_a = 5; // 编译通过 |
const左值引用不会修改指向值,因此可以指向右值,这也是为什么要使用const &作为函数参数的原因之一,如std::vector的push_back:
1 | void push_back (const value_type& val); |
如果没有const,vec.push_back(5)这样的代码就无法编译通过了。
再看下右值引用,右值引用的标志是&&,顾名思义,右值引用专门为右值而生,可以指向右值,不能指向左值:
1 | int &&ref_a_right = 5; // ok |
下边的论述比较复杂,也是本文的核心,对理解这些概念非常重要。
有办法,std::move:
1 | int a = 5; // a是个左值 |
在上边的代码里,看上去是左值a通过std::move移动到了右值ref_a_right中,那是不是a里边就没有值了?并不是,打印出a的值仍然是5。
std::move是一个非常有迷惑性的函数,不理解左右值概念的人们往往以为它能把一个变量里的内容移动到另一个变量,但事实上std::move移动不了什么,唯一的功能是把左值强制转化为右值,让右值引用可以指向左值。其实现等同于一个类型转换:static_cast<T&&>(lvalue)。 所以,单纯的std::move(xxx)不会有性能提升,std::move的使用场景在第三章会讲。
同样的,右值引用能指向右值,本质上也是把右值提升为一个左值,并定义一个右值引用通过std::move指向该左值:
1 | int &&ref_a = 5; |
被声明出来的左、右值引用都是左值。 因为被声明出的左右值引用是有地址的,也位于等号左边。仔细看下边代码:
1 | // 形参是个右值引用 |
看完后你可能有个问题,std::move会返回一个右值引用int &&,它是左值还是右值呢? 从表达式int &&ref = std::move(a)来看,右值引用ref指向的必须是右值,所以move返回的int &&是个右值。所以右值引用既可能是左值,又可能是右值吗? 确实如此:右值引用既可以是左值也可以是右值,如果有名称则为左值,否则是右值。
或者说:作为函数返回值的 && 是右值,直接声明出来的 && 是左值。 这同样也符合第一章对左值,右值的判定方式:其实引用和普通变量是一样的,int &&ref = std::move(a)和 int a = 5没有什么区别,等号左边就是左值,右边就是右值。
最后,从上述分析中我们得到如下结论:
1 | void f(const int& n) { |
按上文分析,std::move只是类型转换工具,不会对性能有好处;右值引用在作为函数形参时更具灵活性,看上去还是挺鸡肋的。他们有什么实际应用场景吗?
在实际场景中,右值引用和std::move被广泛用于在STL和自定义类中实现移动语义,避免拷贝,从而提升程序性能。 在没有右值引用之前,一个简单的数组类通常实现如下,有构造函数、拷贝构造函数、赋值运算符重载、析构函数等。深拷贝/浅拷贝在此不做讲解。
1 | class Array { |
该类的拷贝构造函数、赋值运算符重载函数已经通过使用左值引用传参来避免一次多余拷贝了,但是内部实现要深拷贝,无法避免。 这时,有人提出一个想法:是不是可以提供一个移动构造函数,把被拷贝者的数据移动过来,被拷贝者后边就不要了,这样就可以避免深拷贝了,如:
1 | class Array { |
这么做有2个问题:
temp_array是个const左值引用,无法被修改,所以temp_array.data_ = nullptr;这行会编译不过。当然函数参数可以改成非const:Array(Array& temp_array, bool move){...},这样也有问题,由于左值引用不能接右值,Array a = Array(Array(), true);这种调用方式就没法用了。可以发现左值引用真是用的很不爽,右值引用的出现解决了这个问题,在STL的很多容器中,都实现了以右值引用为参数的移动构造函数和移动赋值重载函数,或者其他函数,最常见的如std::vector的push_back和emplace_back。参数为左值引用意味着拷贝,为右值引用意味着移动。
1 | class Array { |
如何使用:
1 | // 例1:Array用法 |
1 | // 例2:std::vector和std::string的实际例子 |
在vector和string这个场景,加个std::move会调用到移动语义函数,避免了深拷贝。
除非设计不允许移动,STL类大都支持移动语义函数,即可移动的。 另外,编译器会默认在用户自定义的class和struct中生成移动语义函数,但前提是用户没有主动定义该类的拷贝构造等函数(具体规则自行百度哈)。 因此,可移动对象在<需要拷贝且被拷贝者之后不再被需要>的场景,建议使用std::move触发移动语义,提升性能。
1 | moveable_objecta = moveable_objectb; |
还有些STL类是move-only的,比如unique_ptr,这种类只有移动构造函数,因此只能移动(转移内部对象所有权,或者叫浅拷贝),不能拷贝(深拷贝):
1 | std::unique_ptr<A> ptr_a = std::make_unique<A>(); |
std::move本身只做类型转换,对性能无影响。 我们可以在自己的类中实现移动语义,避免深拷贝,充分利用右值引用和std::move的语言特性。
和std::move一样,它的兄弟std::forward也充满了迷惑性,虽然名字含义是转发,但他并不会做转发,同样也是做类型转换.
与move相比,forward更强大,move只能转出来右值,forward都可以。
std::forward<T>(u)有两个参数:T与 u。 a. 当T为左值引用类型时,u将被转换为T类型的左值; b. 否则u将被转换为T类型右值。
举个例子,有main,A,B三个函数,调用关系为:main->A->B,建议先看懂2.3节对左右值引用本身是左值还是右值的讨论再看这里:
1 | void B(int&& ref_r) { |
例2:
1 | void change2(int&& ref_r) { |
上边的示例在日常编程中基本不会用到,std::forward最主要运于模版编程的参数转发中,想深入了解需要学习万能引用(T &&)和引用折叠(eg:& && → ?)等知识,本文就不详细介绍这些了。
英文:Fsf,翻译:Linux中国/robot527
原始地址
• break — 在指定的行或函数处设置断点,缩写为 b
• info breakpoints — 打印未删除的所有断点,观察点和捕获点的列表,缩写为 i b
• disable — 禁用断点,缩写为 dis
• enable — 启用断点
• clear — 清除指定行或函数处的断点
• delete — 删除断点,缩写为 d
• tbreak — 设置临时断点,参数同 break,但在程序第一次停住后会被自动删除
• watch — 为表达式(或变量)设置观察点,当表达式(或变量)的值有变化时,暂停程序执行
• step — 单步跟踪,如果有函数调用,会进入该函数,缩写为 s
• reverse-step — 反向单步跟踪,如果有函数调用,会进入该函数
• next — 单步跟踪,如果有函数调用,不会进入该函数,缩写为 n
• reverse-next — 反向单步跟踪,如果有函数调用,不会进入该函数
• return — 使选定的栈帧返回到其调用者
• finish — 执行直到选择的栈帧返回,缩写为 fin
• until — 执行直到达到当前栈帧中当前行后的某一行(用于跳过循环、递归函数调用),缩写为 u
• continue — 恢复程序执行,缩写为 c
• print — 打印表达式 EXP 的值,缩写为 p
• x — 查看内存
• display — 每次程序停止时打印表达式 EXP 的值(自动显示)
• info display — 打印早先设置为自动显示的表达式列表
• disable display — 禁用自动显示
• enable display — 启用自动显示
• undisplay — 删除自动显示项
• help — 打印命令列表(带参数时查找命令的帮助),缩写为 h
• attach — 挂接到已在运行的进程来调试
• run — 启动被调试的程序,缩写为 r
• backtrace — 查看程序调用栈的信息,缩写为 bt
• ptype — 打印类型 TYPE 的定义
使用 break 命令(缩写 b)来设置断点。
用法:
• break 当不带参数时,在所选栈帧中执行的下一条指令处设置断点。
• break
• break
• break -N break +N 在当前源码行前面或后面的 N 行开始处打断点,N 为正整数。
• break filename:linenum 在源码文件 filename 的 linenum 行处打断点。
• break filename:function 在源码文件 filename 的 function 函数入口处打断点。
• break 在程序指令的地址处打断点。
• break … if
查看断点,观察点和捕获点的列表。
用法:
• info breakpoints [list...]
• info break [list...]
• list... 用来指定若干个断点的编号(可省略),可以是 2, 1-3, 2 5 等。
禁用一些断点。参数是用空格分隔的断点编号。要禁用所有断点,不加参数。
禁用的断点不会被忘记,但直到重新启用才有效。
用法:
• disable [breakpoints] [list...]
• breakpoints 是 disable 的子命令(可省略),list... 同 info breakpoints 中的描述。
启用一些断点。给出断点编号(以空格分隔)作为参数。没有参数时,所有断点被启用。
用法:
• enable [breakpoints] [list...] 启用指定的断点(或所有定义的断点)。
• enable [breakpoints] once list... 临时启用指定的断点。GDB 在停止您的程序后立即禁用这些断点。
• enable [breakpoints] delete list... 使指定的断点启用一次,然后删除。一旦您的程序停止,GDB 就会删除这些断点。等效于用 tbreak 设置的断点。
breakpoints 同 disable 中的描述。
在指定行或函数处清除断点。参数可以是行号,函数名称或 * 跟一个地址。
用法:
• clear 当不带参数时,清除所选栈帧在执行的源码行中的所有断点。
• clear <function>, clear <filename:function> 删除在命名函数的入口处设置的任何断点。
• clear <linenum>, clear <filename:linenum> 删除在指定的文件指定的行号的代码中设置的任何断点。
• clear <address> 清除指定程序指令的地址处的断点。
删除一些断点或自动显示表达式。参数是用空格分隔的断点编号。要删除所有断点,不加参数。
用法: delete [breakpoints] [list…]
设置临时断点。参数形式同 break 一样。
除了断点是临时的之外,其他同 break 一样,所以在命中时会被删除。
为表达式设置观察点。
用法: watch [-l|-location]
如果给出了 -l 或者 -location,则它会对 expr 求值并观察它所指向的内存。例如,watch *(int *)0x12345678 将在指定的地址处观察一个 4 字节的区域(假设 int 占用 4 个字节)。
单步执行程序,直到到达不同的源码行。
用法: step [N] 参数 N 表示执行 N 次(或由于另一个原因直到程序停止)。
警告:如果当控制在没有调试信息的情况下编译的函数中使用 step 命令,则执行将继续进行,直到控制到达具有调试信息的函数。 同样,它不会进入没有调试信息编译的函数。
要执行没有调试信息的函数,请使用 stepi 命令,详见后文。
反向单步执行程序,直到到达另一个源码行的开头。
用法: reverse-step [N] 参数 N 表示执行 N 次(或由于另一个原因直到程序停止)。
单步执行程序,执行完子程序调用。
用法: next [N]
与 step 不同,如果当前的源代码行调用子程序,则此命令不会进入子程序,而是将其视为单个源代码行,继续执行。
反向步进程序,执行完子程序调用。
用法: reverse-next [N]
如果要执行的源代码行调用子程序,则此命令不会进入子程序,调用被视为一个指令。
参数 N 表示执行 N 次(或由于另一个原因直到程序停止)。
您可以使用 return 命令取消函数调用的执行。如果你给出一个表达式参数,它的值被用作函数的返回值。
用法: return
执行直到选定的栈帧返回。
用法: finish 返回后,返回的值将被打印并放入到值历史记录中。
执行直到程序到达当前栈帧中当前行之后(与 break 命令相同的参数)的源码行。此命令用于通过一个多次的循环,以避免单步执行。
用法:until
在信号或断点之后,继续运行被调试的程序。
用法: continue [N] 如果从断点开始,可以使用数字 N 作为参数,这意味着将该断点的忽略计数设置为 N - 1(以便断点在第 N 次到达之前不会中断)。如果启用了非停止模式(使用 show non-stop 查看),则仅继续当前线程,否则程序中的所有线程都将继续。
求值并打印表达式 EXP 的值。可访问的变量是所选栈帧的词法环境,以及范围为全局或整个文件的所有变量。
用法:
• print [expr] 或 print /f [expr] expr 是一个(在源代码语言中的)表达式。
默认情况下,expr 的值以适合其数据类型的格式打印;您可以通过指定 /f 来选择不同的格式,其中 f 是一个指定格式的字母;详见输出格式。
如果省略 expr,GDB 再次显示最后一个值。
要以每行一个成员带缩进的格式打印结构体变量请使用命令 set print pretty on,取消则使用命令 set print pretty off。
可使用命令 show print 查看所有打印的设置。
检查内存。
用法: x/nfu
n 重复次数(默认值是 1),指定要显示多少个单位(由 u 指定)的内存值。
f 显示格式(初始默认值是 x),显示格式是 print(‘x’,’d’,’u’,’o’,’t’,’a’,’c’,’f’,’s’) 使用的格式之一,再加 i(机器指令)。
u 单位大小,b 表示单字节,h 表示双字节,w 表示四字节,g 表示八字节。
例如:
x/3uh 0x54320 表示从地址 0x54320 开始以无符号十进制整数的格式,双字节为单位来显示 3 个内存值。
x/16xb 0x7f95b7d18870 表示从地址 0x7f95b7d18870 开始以十六进制整数的格式,单字节为单位显示 16 个内存值。
每次程序暂停时,打印表达式 EXP 的值。
用法: display
对于格式 i 或 s,或者包括单位大小或单位数量,将表达式 addr 添加为每次程序停止时要检查的内存地址。
打印自动显示的表达式列表,每个表达式都带有项目编号,但不显示其值。
包括被禁用的表达式和不能立即显示的表达式(当前不可用的自动变量)。
取消某些表达式在程序暂停时的自动显示。参数是表达式的编号(使用 info display 查询编号)。不带参数表示取消所有自动显示表达式。
delete display 具有与此命令相同的效果。
禁用某些表达式在程序暂停时的自动显示。禁用的显示项目不会被自动打印,但不会被忘记。 它可能稍后再次被启用。
参数是表达式的编号(使用 info display 查询编号)。不带参数表示禁用所有自动显示表达式。
启用某些表达式在程序暂停时的自动显示。
参数是重新显示的表达式的编号(使用 info display 查询编号)。不带参数表示启用所有自动显示表达式。
打印命令列表。
您可以使用不带参数的 help(缩写为 h)来显示命令的类别名的简短列表。
使用 help
挂接到 GDB 之外的进程或文件。该命令可以将进程 ID 或设备文件作为参数。
对于进程 ID,您必须具有向进程发送信号的权限,并且必须具有与调试器相同的有效的 uid。
用法: attach
无论是通过 attach 命令挂接的进程还是通过 run 命令启动的进程,您都可以使用的 GDB 命令来检查和修改挂接的进程。
启动被调试的程序。
可以直接指定参数,也可以用 set args 设置(启动所需的)参数。
例如: run arg1 arg2 … 等效于
set args arg1 arg2 …
run
还允许使用 >、 < 或 >> 进行输入和输出重定向。
打印整体栈帧信息。
• bt 打印整体栈帧信息,每个栈帧一行。
• bt n 类似于上,但只打印最内层的 n 个栈帧。
• bt -n 类似于上,但只打印最外层的 n 个栈帧。
• bt full n 类似于 bt n,还打印局部变量的值。
where 和 info stack(缩写 info s) 是 backtrace 的别名。调用栈信息类似如下:
1 | (gdb) where |
打印类型 TYPE 的定义。
用法: ptype[/FLAGS] TYPE-NAME | EXPRESSION
参数可以是由 typedef 定义的类型名, 或者 struct STRUCT-TAG 或者 class CLASS-NAME 或者 union UNION-TAG 或者 enum ENUM-TAG。
根据所选的栈帧的词法上下文来查找该名字。
类似的命令是 whatis,区别在于 whatis 不展开由 typedef 定义的数据类型,而 ptype 会展开,举例如下:
1 | /* 类型声明与变量定义 */ |
这两个命令给出了如下输出:
1 | (gdb) whatis var |
这几年一直在linux上开发,用的gcc版本比较高,最近把gcc降到4.8.5(centos 7默认版本)后,出现了一些成员变量初始化的问题。
看示例:
1 |
|
| 编译器 | debug | release |
|---|---|---|
| gcc 4.8 | 2147483647或者-2147483648 |
0 |
| gcc 8.3 | 0 | 0 |
| gcc 9.3 | 0 | 0 |
| vs2019 msvc 142 | 随机数 | 0 |
| clang 7 | 随机数 | 随机数 |
| clang 10 x86 | 1 | 随机数 |
| clang 10 x64 | 0 | 随机数 |
gcc 4.8 好像不同硬件上会不一样,在另一 服务器上测试都为0
看来还是使用旧式显式初始化靠谱一些,或者这样写int m_a = 0;使用c++11方式进行初始化
如果哪天如果有人问我这种问题,我应该怎么回答呢?是不是要把高版本给过滤掉,像上学时回答考试问题一样。。。
MiniDumper(LPCTSTR DumpFileNamePrefix)
MiniDumper(LPCTSTR DumpFileNamePrefix, LPCTSTR CmdLine, LPCTSTR ExeNameToReboot /* = NULL */)
DumpFileNamePrefix 崩溃文件名前缀
CmdLine 生成崩溃文件后执行命令(包含参数)
ExeNameToReboot 生成崩溃文件后执行指定程序
在崩溃时调用指定的程序,下面的示例是调用CrashReport.exe上传到指定的服务器
1 |
|
MiniDumper 初始化时调用 Win32 API SetUnhandledExceptionFilter 注册过滤函数TopLevelFilter,
当发生崩溃时会调用TopLevelFilter生成minidump文件,其过程如下:
DBGHELP.DLL,并定位到MiniDumpWriteDump函数地址MiniDumpWriteDump函数生成DumpFileNamePrefix前缀的minidump文件ContextDump函数生成当前堆栈日志文件CmdLine如果指定,这里一般会调用上传程序把相关日志记录上传到远程服务器,由工程师统一调查处理。ExeNameToReboot如果指定其实很早就知道两个函数其中有一个在面临内存覆盖时行为有点特别, 但是工作中很少用到此场景, 也就没有深究. 现在居然面试遇到了, 那就把研究清楚吧.
综上所述, 以后干脆就用memmove吧. 省的那么多事. 反正性能几乎没有损失.
1 | int main(int argc, char **args) |
1 | original str : hello world |
glibc 2.17 的memmove源码如下
1 | rettype |