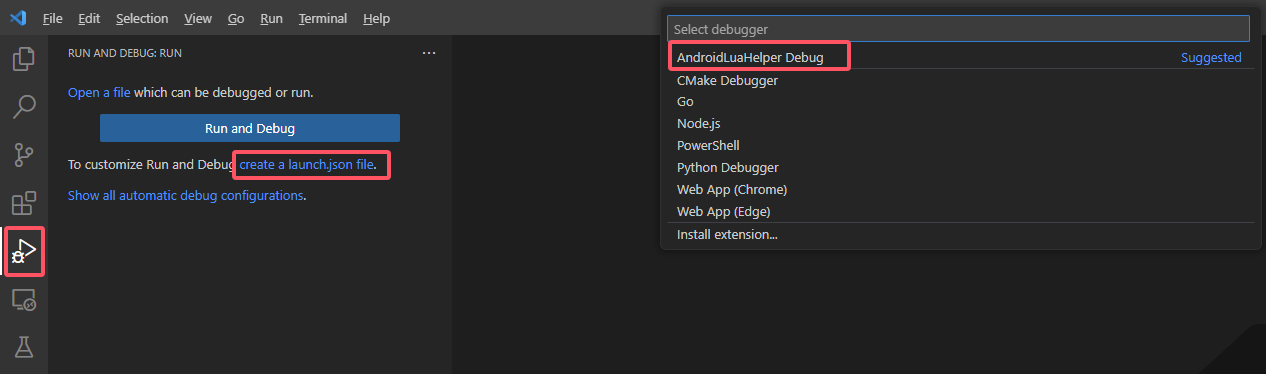
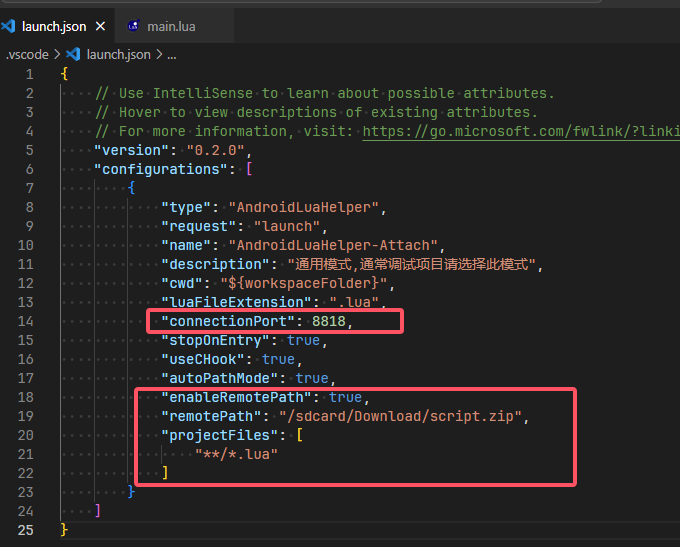
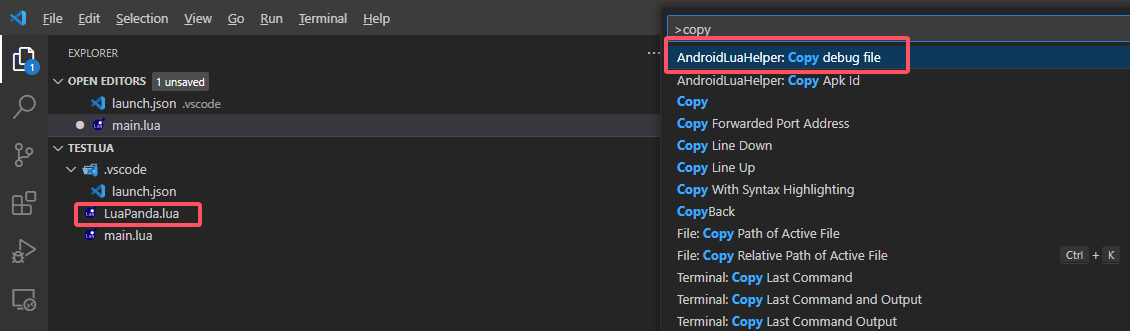
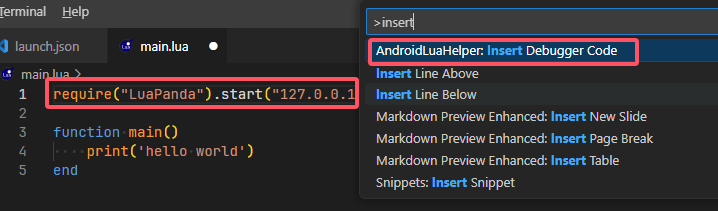
计算机简史
阿兰·图灵
说到计算机的历史,就不得不提到一个人——图灵,那么图灵是什么人?

阿兰·图灵,英国著名的数学家和计算机科学家,被誉为计算机科学之父、人工智能之父和密码学之父。
第二次世界大战中,阿兰·图灵是一位密码破译专家,协助英国政府破解了德国的密码,对盟军的胜利作出了贡献。
在1939年,英国参加了二战,他加入英国布莱切利园的一个密码破译组织,负责破解德军用的一种名为 Enigma 加密机的通信加密信息。

Enigma 看起来像一台打字机,有键盘、灯板、插线板和转子。键盘上按下一个字母键,灯板就会显示加密后的字母。
其中最重要的是转子,Enigma 的转子会轮换替代映射到密文。更改映射的能力很重要,因为一旦某人推导出一个字母替代规则,那么他将会知道密文中每个字母替换规则,因此需要将这些配对都改变,每次编码字母时都更改。
Enigma 实现方式是将所有布线嵌入到车轮/转子中。通过在保持字母静止的同时转动转子,字母之间的连接会发生变化。重复替换步骤,然后转动每个字母的转子。在转子中,每根导线的两端都有外部接触点。这允许这些转子中的多个并排放置,相邻触点接触。在内部,每个转子的接线方式不同,即每个转子都包含不同的密码。在一些Enigma机器中,有三个转子,最常用的是八个。每个转子还有一个附加的字母环,该字母环随转子转动并用于设置转子的初始位置。
每个转子都可以转动到任何位置。这意味着对于第一个转子,有26条可能的路径通过一个字母。但是一旦我们沿着导线穿过第一个转子,现在有26条可能的路径通过第二个转子。然后通过第三条路径还有26条可能的路径。因此,2条通过所有三个转子的路径总数为17576。如果是5个转子,我们可以从五个转子中选择用于左侧的转子,然后从剩余的四个转子中选择用于中间的转子,然后从三个转子中选择用于正确的转子。这提供了60种可能的方式来选择用于消息的三个转子。由于一个字母可以通过转子有17576条可能的路径,因此总共有1054560种可能性。
1930年,德国军队版本增加了一个插板,允许交换字母。由于有26个字母,最多可以进行13个掉期,但通常只有10个。计算连接插板的可能方法数量的数学有点复杂,但数字是150738274937250。乘以我们上面给出的其他可能的组合,我们得到一个字母可以采用的可能路径总数是158962555217826360000。
可能性超多的,在那个只能用真空管做布尔计算的时代,想要破译这些可能,是一件很难的事情。
那么当时盟军是怎么破译的呢?
早期替换加密规律很简单,比如凯撒加密把信件中的字母向前挪三个位置,还有玛丽女王密谋杀伊丽莎白女王的密文,通过统计字母出现频率之类的规则,当破解了一个字母替换方法就能找出通篇原文,没有计算机也能够手工破解出来,而 Enigma 每个字母的可能性都海量的,导致盟军在很长一段时间都没法破译 Enigma 加密的内容。
1932年波兰数学家马里安·雷耶夫斯基、杰尔兹·罗佐基和亨里克·佐加尔斯基按照法国情报人员秘密获取的 Enigma 的原理破解了 Enigma。由于波兰数学家们利用的漏洞不断被德军修复,算力无法及时算出结果,后来将破解方法告诉了英国。

图灵基于波兰破解方法,利用字母加密后一定会是一个和自己不同的字母这个缺陷,设计了一个叫 Bombe 的计算机,对加密消息尝试多种组合,如发现字母解密后和原先一样,这个组合就会被跳过,接着试另一组,因此 Bombe 大幅减少了搜索量,这样就能保证及时破解信息。
战争历史学家 Harry Hinsley 肯定了图灵和布莱切利园组织的工作,说由于他们的工作让战争缩短了两年多,挽救了1400万人的生命。
加密算法
如今加密技术怎样了呢?进入民用了么?我们能够利用加密技术保护我们的数据安全吗?
对称加密算法
加密技术从硬件转向了软件,早期加密算法是1977年的 DES。DES 是一种对称加密算法,它的原理是将明文分成64位的块,通过一系列的置换、替换和移位操作,使用一个56位的密钥对明文进行加密,得到64位的密文。意味着有2的56次方,或大约72千万亿个不同密钥。当时是没有计算能力可以暴力破解所有可能密钥的。
DES 加密算法的具体步骤如下:
- 初始置换(IP):将明文按照一定的规则进行置换,得到一个新的64位明文。
- 分组:将置换后的明文分成左右两个32位的块。
- 轮函数:对右半部分进行一系列的置换、替换和移位操作,使用一个48位的子密钥对其进行加密。
- 左右交换:将左半部分和右半部分进行交换。
- 重复执行第3步和第4步,共进行16轮。
- 合并:将左右两个32位的块合并成一个64位的块。
- 末置换(FP):将合并后的块按照一定的规则进行置换,得到一个新的64位密文。
DES 解密算法的步骤与加密算法相反,主要是将加密算法中的子密钥按照相反的顺序使用,对密文进行解密。
DES 加密算法的安全性在当时是比较高的。
到了1999年,计算机芯片计算能力指数增加,一台计算机就能在几天内将 DES 的所有可能密钥都试一遍。因此,DES 已经不再被广泛使用,取而代之的是更加安全的加密算法,例如 AES。
2001年 AES 是一种对称加密算法,它的原理是将明文分成128位的块,通过一系列的置换、替换和移位操作,使用一个128位、192位或256位的密钥对明文进行加密,得到128位的密文。
AES 加密算法的具体步骤如下:
- 密钥扩展:根据密钥长度,对密钥进行扩展,生成多个轮密钥。
- 初始轮:将明文按照一定的规则进行置换,得到一个新的128位明文。
- 轮函数:对明文进行一系列的置换、替换和移位操作,使用一个轮密钥对其进行加密。
- 重复执行第3步,共进行多轮。
- 末轮:对明文进行最后一轮的置换、替换和移位操作,使用最后一个轮密钥对其进行加密。
- 得到密文。
AES 解密算法的步骤与加密算法相反,主要是将加密算法中的轮密钥按照相反的顺序使用,对密文进行解密。
AES 加密算法的安全性很高,主要基于其密钥长度和轮函数的复杂性。AES 支持三种密钥长度:128位、192位和256位,其中256位密钥的安全性最高。此外,AES 的轮函数使用了多种复杂的操作,例如有限域上的乘法和逆变换,使得密码破解变得更加困难。
AES 在性能和安全性间取得平衡。如今 AES 被广泛使用,比如 iPhone 上加密文件,访问 HTTPS 网站等。
进入互联网时代,以前加密技术中的密钥在网上传递过程中会被截获,截获到密钥就能够直接解密通信了。
那要怎么做才能够保证密钥不会被截获呢?
这就要用到密钥交换技术了。

密钥交换是一种不发送密钥,但依然让两台计算机在密钥上达成共识的算法。我们可以用单向函数来做。单向函数是一种数学操作,很容易算出结果,但想从结果逆向推算出输入非常困难。
密钥交换的原理是基于数学问题的难解性,例如离散对数问题。
其中,Diffie-Hellman 密钥交换协议是一种常见的密钥交换协议,在 Diffie-Hellman 里单向函数是模幂运算。意思是先做幂运算,拿一个数字当底数,拿一个数字当指数。其具体原理如下:
- 选择两个大质数 p 和 g,其中 g 是 p 的原根。
- 小明选择一个私钥 a,并计算
A=g^a(mod p),将 A 发送给小强。 - 小强选择一个私钥 b,并计算
B=g^b(mod p),将 B 发送给小明。 - 小明计算
s=B^a(mod p)。 - 小强计算
s=A^b(mod p)。 - 现在,小明和小强都拥有相同的密钥 s,可以在通信过程中使用它来加密和解密消息。
Diffie-Hellman 密钥交换协议的安全性基于离散对数问题的难解性,即使已知 p、g、A 和 B,也很难计算出 a 和 b。因此,Diffie-Hellman 密钥交换协议被广泛应用于安全通信和密钥交换等领域。
另外还可以用混色来比喻 Diffie-Hellman 密钥交换协议。
将颜色混合在一起很容易。但想知道混了什么颜色很难。要试很多种可能才知道,用这个比喻,那么我们的密钥是一种独特的颜色,首先,有一个公开的颜色 C,所有人都可以看到。然后小明和小强各自选一个秘密颜色 A 和颜色 C,只有自己知道,然后小明发给小强 A 和 C 的混色。小强也这样做,把他的秘密颜色 B 和公开颜色 C 混在一起,然后发给小明。小明收到小强的颜色后,把小明的秘密颜色 A 加进去,现在3种颜色混合在一起。小强也一样做。这样,小强和小明就有了一样的颜色。他们可以把这个颜色当密钥,尽管他们从来没有给对方发过这颜色。外部截获信息的人可以知道部分信息,但无法知道最终颜色。
Diffie-Hellman 密钥交换是建立共享密钥的一种方法。双方用一样的密钥加密和解密消息,这叫对称加密,因为密钥一样,凯撒加密,英格玛,AES 都是对称加密。
对称加密的内容两个人都能解密看到,如果加密的信息只想有一方可以解密查看就要用到非对称加密。非对称加密,有两个不同的密钥,一个是公开的,另一个是私有的,用公钥加密消息,只有有私钥的人能解密。
就好像把一个箱子和锁给你,你可以锁上箱子,但不能打开箱子,锁箱子就是公钥加密,能够打开箱子的是有钥匙的人,解锁就是私钥解密。
非对称加密算法
常见的非对称加密算法包括RSA、DSA和ECC等。目前最流行的非对称加密技术是 RSA。名字来自发明者:Rivest,Shamir,Adleman。
RSA 的原理是基于数学问题的难解性,例如大质数分解。RSA的具体原理如下:
- 选择两个大质数 p 和 q,计算它们的乘积
n=p*q。 - 选择一个整数e,使得
1<e<φ(n),且 e 与φ(n)互质,φ(n)=(p-1)*(q-1)。 - 计算 e 关于
φ(n)的模反元素 d,即满足e*d≡1(mod φ(n))的最小正整数 d。 - 公钥为
(n,e),私钥为(n,d)。 - 加密时,将明文 m 转换为整数 M,计算密文
C=M^e(mod n)。 - 解密时,将密文 C 计算出明文 m,即
M=C^d(mod n)。
RSA 的安全性基于大质数分解的难度,即使已知公钥和密文,也很难计算出私钥。因此,RSA被广泛应用于数字签名、密钥交换和安全通信等领域。比如数字签名就是公钥来解密,大家都能公开看到签名内容,只有服务器端能够用私钥来加密,这样就能够证明签名是没有伪造的。
对称加密,密钥交换和公钥密码这些就是现代密码学。和图灵那个时代相比更加安全,加解密速度的提高让应用场景也更加地广泛了。
图灵机
图灵除了密码破译外还做了一件对现代计算机影响深远的事情。
1935年,德国数学家大卫·希尔伯特提出的问题,就是“可判定性问题”,可判定性问题是指是否存在一种算法,输入逻辑语句,可以判断是和否。
图灵发明了一种叫做图灵机的东西,这个机器可以模拟任何其他的计算机,通过图灵机回答了可判定性问题,这个问题虽然看似简单,但是实际上却相当复杂,因为涉及了形式语言的理论、递归的原理等概念。

图灵机可以用于证明停机问题,即判断一个给定的程序是否会在有限时间内停止运行。停机问题是计算机科学中的一个经典问题,它在理论上是不可解的,即不存在一种通用的算法可以解决所有停机问题。这个图灵机可以接受一个程序集合作为输入,并输出一个程序,该程序与输入集合中的所有程序的行为都不同。通过对这个图灵机的构造和分析,图灵证明了停机问题的不可解性。
具体来说,当程序不递归自己,输出停机,测试程序就调用它,使其不停机;如果程序递归调用自己,输出不停机,测试程序不调用它,使其停机。那么问题是测试程序递归调用自己时。
另外还有个更形象的和停机问题一样的理发师悖论,具体说就是有个理发师他有个原则,有人不能刮胡子,他刮;有人刮胡子,他不能刮。无法回答的问题是,理发师会自己刮胡子么?因为他能自己刮,但根据他的原则他又不能刮,但他不能刮的话他又要刮。
图灵机是图灵对计算机的设想,他假设时间足够多,存储足够大,图灵机可以实现任何计算,另外通过停机问题也证明了并不是所有问题都能用计算来解决,也就是提前证明了计算机的极限。开启了可计算性理论,也就是丘奇-图灵论题。

图灵机工作过程和人处理问题的过程类似,获取外部信息,处理当前信息,将处理结果暂存,接下来再获取新的信息重复这个过程。为了完成这个过程,图灵设计的机器有用于输入信息的纸带,处理信息的状态规则,暂存结果的状态寄存器,以及用于获取信息和存储信息的读写器。图灵机的工作过程为:
- 从纸带上读取信息
- 通过状态规则查找状态并按规则执行
- 状态寄存器存储结果
- 进入新状态
- 重复过程
现代计算机的设计和实现受到了图灵机的启发。计算机的核心部件包括中央处理器(CPU)、存储器、输入输出设备等,这些部件的设计和实现都是基于图灵机的模型。例如,CPU 可以看作是图灵机的控制器,存储器可以看作是图灵机的纸带,输入输出设备可以看作是图灵机的输入输出接口。
另外,现代计算机的编程语言和算法也受到了图灵机的影响。图灵机可以模拟任何可计算的问题,因此它可以用来证明某个问题是可计算的,也可以用来设计算法和编写程序。现代计算机的编程语言和算法都是基于图灵机的模型,它们可以用来描述和解决各种计算问题。
总的来说现代计算机实现了图灵对计算机的设想,也深入到了我们每个人的生活。一些本来机器解决不了而人类可以解决的问题,机器也可以通过大量数据学习人类来解决。
计算机硬件发展史
接下来,我先简单介绍下计算机最核心的计算处理控制器发展,是怎么从图灵时代的继电器发展到现代 CPU 的。
上古时代–继电器时代

图灵所在二战时代最大的计算机叫哈佛一号,由哈佛大学和 IBM 公司合作研制,有76万5千个组件,300万个连接点和500英里长的导线。哈佛一号采用电子管和机械继电器作为计算元件,可以进行加、减、乘、除等基本运算,还可以进行对数、三角函数等高级运算。继电器是用电控制机械开关。可以把继电器控制线路想成水龙头,打开水龙头,水会流出来,关闭水龙头,水就没了。只不过继电器控制的是电子而不是水。机械开关速度有限,最好的继电器1秒翻转50次。
哈佛一号的体积庞大,重达 5 吨,占地面积达 51 平方米,需要 3 个人来操作。哈佛一号的设计和实现受到了图灵机的启发,它采用了分程序控制和存储程序的思想,可以根据不同的程序进行自动切换。哈佛一号的设计者之一霍华德·艾肯曾说过:“我们试图建造一台机器,它可以像人一样思考,但是我们失败了。相反,我们建造了一台机器,它可以像机器一样思考。”
哈佛一号的研制历时 11 年,耗资 500 万美元,是当时世界上最先进的计算机之一。
哈佛马克一号一秒3次加减,6秒乘法,15秒除法。更复杂操作比如三角函数需要1分钟以上。除了速度慢,齿轮也容易磨损,继电器数量多故障率也会增加,哈佛马克一号有3500个继电器。昆虫也会造成继电器故障,1947年9月操作员从故障继电器中拔出一只死虫,那时每当电脑出了问题,就说它出了 bug。这个就是术语 bug 的来源。
古代–真空管时代
继电器的替代品是真空管。真空管是一种电子器件,它的工作原理基于热电子发射和电子在真空中的运动。真空管由阴极、阳极和控制网格等部件组成,其中阴极是一个加热的金属丝,当温度升高时,会发射出大量的自由电子。这些电子被加速器电场加速,穿过控制网格,最终撞击到阳极上,产生电流。真空管内通过电流控制开闭实现继电器功能,由于真空管内没有会动的组件,这样速度更快,磨损更少,每秒可以开闭数千次。
真空管的工作过程可以分为三个阶段:发射阶段、传输阶段和收集阶段。在发射阶段,阴极发射出大量的自由电子,这些电子被加速器电场加速,形成电子流。在传输阶段,电子流穿过控制网格,受到网格电场的控制,形成一个电子束。在收集阶段,电子束撞击到阳极上,产生电流。
真空管的工作原理与晶体管等现代电子器件不同,它需要加热阴极才能发射电子,因此功耗较大,体积较大,寿命较短。但是真空管具有高功率、高频率、高压等特点,在一些特殊的应用场合仍然得到广泛应用。
真空管很贵,收音机一般只用一个,但计算机可能要上百甚至上千个。一般只有政府才会使用真空管做计算机。第一个大规模用真空管做的计算机是巨人一号,由工程师 Tommy Flower 设计,1943年12月完成。巨人一号在英国的布莱切利园里,用来破解日本的通信。巨人一号是基于图灵机的原理设计的,它采用了存储程序的思想,可以自动执行多个程序。同在布莱切利园的图灵的 bombe 机器没有使用真空管,而是使用的机械装置。核心部件是旋转轮机,它通过模拟密码机的运行过程来破解密码。Bombe 机器的工作原理与真空管电子计算机不同,它不需要电子元件,而是通过机械装置来实现计算和控制。巨人一号和图灵的 bombe 机器在破解密码的方式上也存在一些区别。巨人一号主要使用了穷举法和字典攻击等方法,而图灵的 bombe 则主要使用了差分密码分析等方法。
近现代–半导体时代
晶体管
计算机硬件技术真正实现突破沿用至今的时刻发生在1947年,当年为了降低计算机成本和大小,同时提高可靠性和速度,1947年贝尔实验室科学家 John Bardeen,Walter Brattain,William Shockley 发明了晶体管。晶体管由三个掺杂不同材料的半导体层构成,其中中间的层被称为基底,两侧的层被称为掺杂层。当掺杂层中注入电子或空穴时,它们会在基底中形成一个电子或空穴浓度较高的区域,这个区域被称为 PN 结。PN 结可以用来控制电流的流动,从而实现放大和开关电信号的功能。晶体管的发明是电子技术史上的重要里程碑,它的出现标志着电子器件从真空管时代进入了半导体时代。
晶体管的物理学相当复杂,牵扯到量子力学。晶体管有两个电极,电极之间有一种材料隔开他们,这种材料有时候导电,有时候不导电,叫半导体。半导体每秒可以开关10000次,与玻璃制作的真空管相比,晶体管是固态的,不容易坏,而且比真空管更小更便宜。
1957年 IBM 推出完全用晶体管的 IBM 608,由于便宜,消费者也可以买得到。它有3000个晶体管,每秒执行4500次加法,80次乘除法。IBM 将晶体管计算机带入千家万户。现在计算机里的晶体管小于50纳米,而一张纸的厚度大概是10万纳米。每秒可以切换上百万次,工作很多年。
晶体管和半导体的开发在圣克拉拉谷,半导体材料大部分是硅,硅很特别,它是半导体,它有时导电,有时不导电,我们可以控制导电时机,所以硅是做晶体管的绝佳材料。硅的蕴藏量丰富,占地壳四分之一,这个地方后来被称为硅谷。
集成电路
1960年代,为了解决电子器件体积大、功耗高、可靠性差等问题。在德州仪器工作的 Jack Killby 把多个组件包在一起,变成一个新的独立组件,这个组件就是集成电路。Robert Noyce 的仙童半导体让集成电路变为现实。最开始一个 IC 只有几个晶体管,把简单电路,逻辑门封装成单独组件。
在集成电路中,数百万个晶体管、电容器、电阻器等元件被集成在一个芯片上,从而大大减小了电路的体积和功耗,提高了电路的可靠性和性能。
在集成电路出现之前,电子器件主要采用离散元件的方式进行组装。这种方式需要大量的电子元件,而且需要手工进行组装和连接,不仅体积大、功耗高,而且可靠性差。随着半导体技术的发展,人们开始尝试将多个晶体管、电容器、电阻器等元件集成在一个芯片上,从而形成了集成电路。
集成电路的出现极大地推动了电子技术的发展。它不仅使电子器件的体积和功耗大大减小,而且提高了电路的可靠性和性能。随着集成电路技术的不断发展,芯片上的晶体管数量不断增加,集成度不断提高。
为了创造更复杂的电路并能够大规模生产,出现了通过蚀刻金属线的方式,把零件连接到一起的印刷电路板技术,简称 PCB。是一种用于连接和支持电子元件的基板,它通过在表面覆盖一层导电材料(通常是铜)并在其上刻蚀出电路图案,从而实现电路的连接和布局。印刷电路板广泛应用于电子设备中,例如计算机、手机、电视等。
印刷电路板的制作过程通常包括以下几个步骤:
- 设计电路图:首先需要根据电路的功能和布局设计电路图,通常使用电路设计软件进行设计。
- 制作印刷电路板:将电路图转换为印刷电路板的图案,并使用光刻技术将图案转移到覆盖在基板上的光阻膜上。然后,使用化学蚀刻技术将未被光阻膜保护的铜层蚀刻掉,从而形成电路图案。
- 镀金层:在印刷电路板表面镀上一层金属,通常是镀金,以提高电路板的导电性和耐腐蚀性。
- 焊接元件:将电子元件焊接到印刷电路板上,通常使用表面贴装技术(Surface Mount Technology,SMT)或插件式技术(Through-Hole Technology,THT)。
- 测试电路板:使用测试设备对印刷电路板进行测试,以确保电路板的功能和性能符合要求。
为了在相同体积下集成更多晶体管,全新的光刻工艺出现了,用光把复杂图案印到材料上,比如半导体。其基本原理是利用光敏材料对光的敏感性,通过光的照射和化学反应来形成所需的图案。光刻使用材料包括光掩膜,光刻胶,金属化,氧化层和晶圆。我们可以用晶圆做基础,把复杂金属电路放上面,集成所有东西,非常适合做集成电路。
光刻的基本步骤包括:
- 涂覆光刻胶:将光刻胶涂覆在待加工的基板表面上,形成一层均匀的薄膜。
- 曝光:将光刻胶暴露在紫外线下,通过掩膜将光刻胶暴露在特定的区域,形成所需的图案。
- 显影:将光刻胶进行显影,将未暴露在紫外线下的光刻胶溶解掉,形成所需的图案。
- 退光刻胶:使用退光刻胶剂将光刻胶进行退除,以便进行下一步的工艺步骤。
在曝光过程中,光刻胶中的光敏剂会吸收光子能量,从而发生化学反应,使得光刻胶在曝光区域发生物理或化学变化。在显影过程中,未曝光的光刻胶会被溶解掉,而曝光区域的光刻胶则会保留下来,形成所需的图案。在退光刻胶过程中,使用退光刻胶剂将光刻胶进行退除,以便进行下一步的工艺步骤。
用类似制作步骤,光刻可以制作其他电子元件,比如电阻和电容,都在一片硅上。而且互相连接的电路也做好了。现实中,光刻法一次会做上百万个细节。
有了光刻技术晶体管越来越小,密度也变得更高,戈登·摩尔发现了一个趋势,就是每两年相同空间所放晶体管数量会增加两倍,后来这个规律被称为摩尔定律。戈登·摩尔和罗伯特·诺伊斯联手成立了一家新公司,结合 Intergrated 和 Electronics 两个词,取名 Intel,是现在最大的芯片制造商。CPU 晶体管数量按摩尔定律一直在指数级地增长,1980年,一个芯片有3万晶体管。到1990年达到了100万,2010年一个芯片里已经可以放进10亿晶体管,现在苹果 M1 Ultra 的晶体管数量约为1140亿。英特尔说,到2030年,芯片将拥有约1万亿个晶体管。先进的芯片中晶体管的尺寸是以纳米为单位,小到2纳米,比血红细胞小2800倍。除了 CPU 还有内存,显卡,固态硬盘和摄像头感光元件等都得益于光刻带来的摩尔定律发展。现在的电路设计都是超大规模集成(VLSI)自动生成的设计。
目前由于光的波长精度已经接近极限,因此需要波长更短的光源来投射更小图案。另外晶体管小到一定程度电极之间可能只有原子长,会发生量子隧道贯穿,也就是电子会跳过间隙。不过相信只要有需求,这些技术问题终将被克服。
那么究竟都有什么样的需求一直推动着计算机技术爆发增长呢?

计算机软件发展史
最早计算机的用途主要就是做数学计算,比如二战的炮手,需要根据射程和大气压力来计算近似多项式,多项式可以描述几个变量的关系,这些函数手算很麻烦耗时。Charles Babbage 提出一种新型机械装置叫差分机将欲求多项方程的前3个初始值输入到机器,推论出固定不变的差数,接下来每个值就可以将差数和前一个阶段的值相加得到。求多项方程的结果完全只需要用到加和减。
在19世纪末,美国人口10年一次普查,然而手工编制需要七年时间,编制完成已经过时了,1890年人口激增,手工编制普查数据需要13年之久。Herman Hollerith 发明了打孔卡片制表机,机器是电动机械的,用传统机械计数,用电动结构连接其他组件。用打孔来表示数据,每个孔代表一个二进制数码,机器会读取孔的位置将其转成数字,打孔卡片制表机的工作方式如下:
- 使用打孔机将有关个人的数据记录在打孔卡片上。在卡片上打孔,代表一个人的姓名、年龄、职业等信息。
- 打好的卡片被送入Hollerith的制表机。该机器有金属刷子,可以从卡片上的孔中穿过。
- 当刷子经过一个开孔时,一个电路就会完成,一个计数器就会递增。计数器记录着有多少张牌具有某些特征。
- 计数器还可以使用连接在机器上的打印机将结果打印在纸上。它将根据计数器的计数来打印数据的摘要。
与手工操作相比,Hollerith的系统加快了数据的统计过程,速度是手动的十倍。美国人口普查局在1890年采用了他的打孔卡系统,使他们能够在两年半内完成人口普查数据处理。
Herman Hollerith 后来成立了制表机器公司,服务于会计、保险评估和库存管理等数据密集行业。后来这家公司和其他公司合并后改名国际商业机器公司,简称 IBM。
二战时期及二战后冷战时期各国对计算机的需求达到了鼎盛,比如我前面提到图灵他们做的破译 Enigma 的机器。政府对计算机投入资源的时期是美国和苏联的冷战,这也得益于二战时计算机在曼哈顿计划和破解德军加密对自身价值的证明。其中阿波罗计划是投入经费最多的项目,雇了40多万人,还有2万多家大学和公司参与了其中。复杂轨道的计算需求是最大的,因此 NASA制造了阿波罗导航计算机,这台计算机首先使用了集成电路,当时首先使用了集成电路的价格是很贵的,一个芯片就需要五十多美元,而阿波罗导航计算机需要上千个这样的芯片。另外军事上,洲际导弹和核弹也促进了集成电路规模化生产。
随着冷战的结束,政府在计算机上的投入也逐渐减少,计算机迎来了家用消费级时代。

70年代初,计算机各个组件的成本都有大幅下降,可以做出低成本适用于个人使用的电脑,第一台取得商业成功的个人计算机是 Altair 8800,很多计算机爱好者都会购买,计算机的程序要用机器码编写,由于编写麻烦,比尔·盖茨编写了 BASIC 解释器,可以将 BASIC 代码转换成可执行机器码,这个解释器叫 Altair BASIC,也是微软的第一个产品。
24岁的 Steve Wozniak 受到 Altair 8800 的启发,做了一台自己的计算机,他的同学 Steve Jobs 看中了其中机会,1976年4月1日创立了苹果计算机公司,1976年7月开始将 Steve Wozniak 设计的计算机进行售卖,这也是苹果计算机公司的第一款产品。后来苹果的 Apple-II 卖了上百万套,苹果公司一战成名。
和苹果的封闭架构不同的是 IBM 发布的 IBM PC,IBM PC 采用的是开放式架构,这样每个公司都可以遵循这个标准做出自己的计算机,核心硬件和外设都可以有不同组合,这样的计算机也称为 IBM 兼容计算机。
开放的架构也繁荣了生态,更多公司比如康柏和戴尔加入了个人计算机领域。
让计算机进入更多普通人家庭的是交互上的革命。
1984年苹果发布了 Macintosh,使用图形界面取代了用命令行交互的终端。
更多用户对计算机的使用也带来视觉和听觉感官的诉求。那么图形和声音是怎么让计算机识别处理和保存的呢?
当一个图像以特定的格式保存时,构成图像的数字数据–像素和它们的颜色值–被编码并根据该格式的规范进行压缩。该文件还包含元数据,如图像大小、分辨率和色彩模式。

图像文件格式决定了数字数据的组织和压缩方式,图像文件格式的主要类型有:
- JPEG:一种 “有损 “的压缩格式,通常用于照片。它压缩图像数据以减少文件大小,导致图像质量的一些损失。
- PNG:一种 “无损 “的压缩格式,适用于带有文字、线条和图形的图像。用这种格式保存时,没有图像质量的损失。
- GIF: 一种适用于颜色数量有限的图像的格式,通常用于网络上的简单图形和动画。
- BMP: 一种未压缩的格式,存储图像的精确像素数据。BMP文件的尺寸往往很大。

数字音频文件是由代表音频波形的二进制数据组成。文件格式规定了这种二进制数据的结构和组织方式,以表示音频样本、比特深度、采样率、通道数量和其他元数据。像媒体播放器这样的计算机程序可以读取文件格式并解码二进制数据以播放音频。
常见的音频文件格式包括:
- WAV:一种标准的未压缩的音频格式,由原始样本组成。WAV文件往往尺寸较大,但具有较高的音频质量。
- MP3: 一种压缩的音频格式,使用有损压缩来减少文件大小。MP3文件较小,但与WAV相比,其音频质量略低。
- AAC: 另一种压缩的音频格式,提供良好的压缩率,同时保持相对较高的音频质量。AAC文件通常用于iPod等设备。
- FLAC: 一种无损压缩的音频格式,在保留所有原始音频信息和质量的同时压缩文件以减小尺寸。
如今,计算机已经可以大致模拟出我们所能感受到的东西,而图灵对计算机的构想也正随着硬件高速发展而逐步被实现,并走进每一个人的生活。关于图灵证明的计算机的极限,计算机已通过学习大量数据来模仿人类进行突破,学会根据情况忽略一些悖论来避免宕机。和计算机不同,我们的生命有限,记忆的容量有限,但也正因为如此,我们才能更好地享受和珍惜每一次对未知事物探索过程的回忆,而不是结果。